Hallo,
seitdem ich das Update auf UCS 4.4-0 durchgeführt habe, frieren alle aktulisierten Server in unregelmäßigen Abständen ein unabhängig voneinander ein. Der eingefrorene Server ist via Ping erreichbar allerdings ist der Server nicht via http oder SSH erreichbar. Eine lokale Anmeldung in der Console scheint im ersten Moment möglich, nachdem ich den Benutzernamen eingegeben habe dauert es aber sehr lange bis zur Passwortabfrage nach dieser passiert dann für mehrere Stunden nichts mehr.
Bisher habe ich den Server dann hart ausgeschaltet, er funktioniert dann für einige Tage wieder unauffällig bis das Problem erneut auftritt.
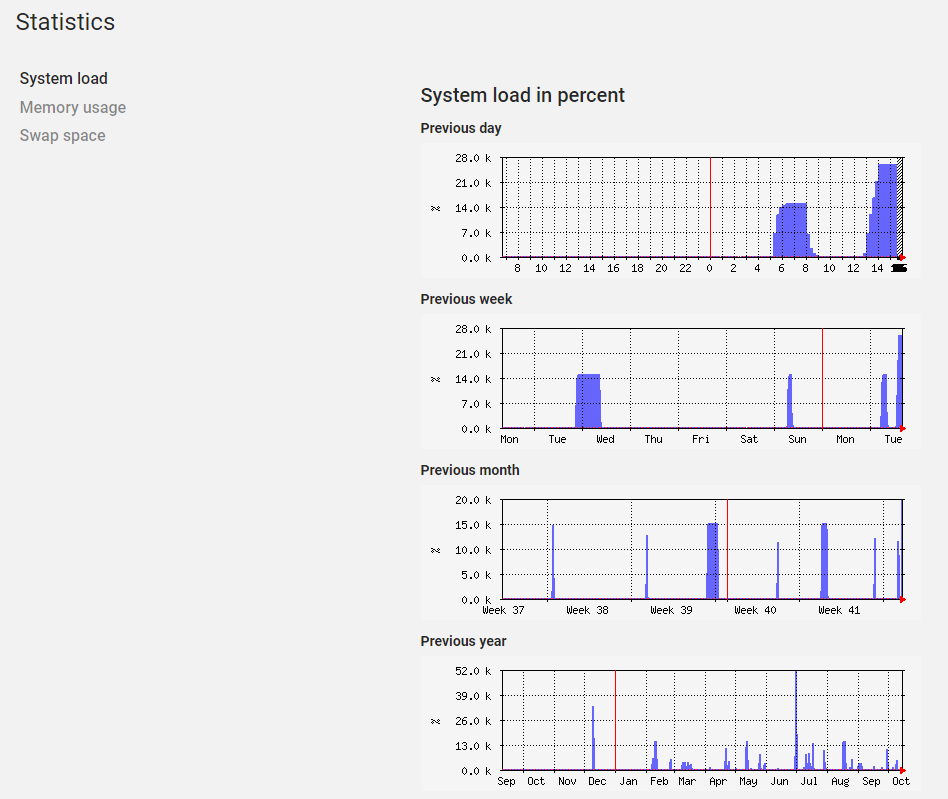
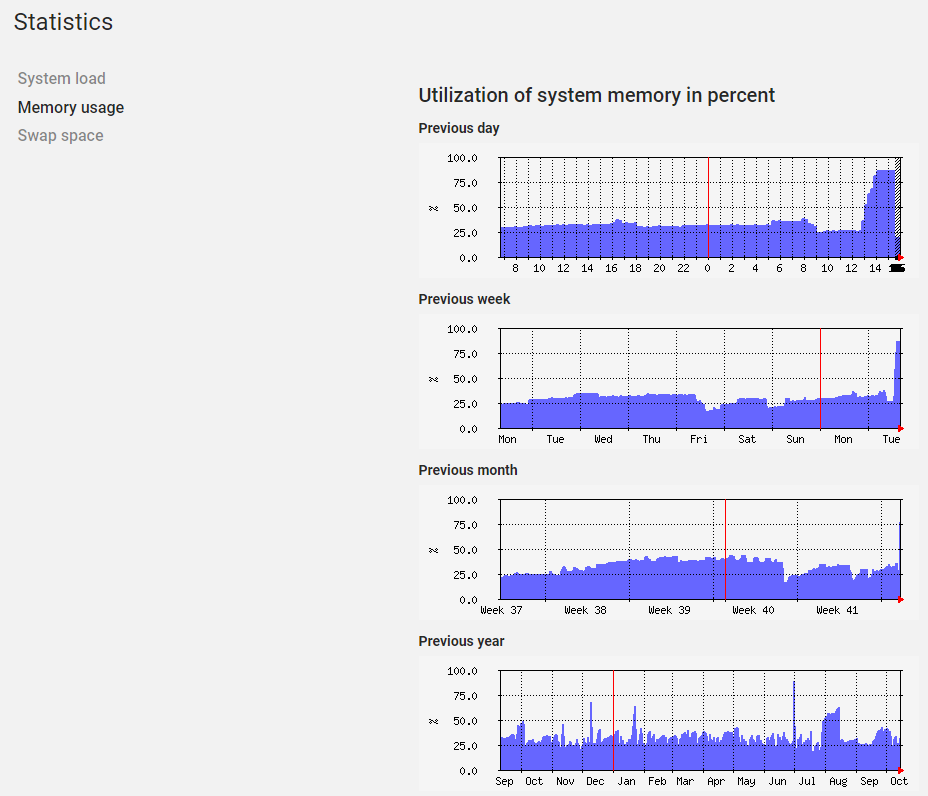
Eine Überprüfung der Logs zeigt, dass der Server irgendwann einfach aufhört irgendetwas zu tun. Ich habe keine nennenswerten Auffälligkeiten gefunden außer, dass der letzte Logfile Eintrag mehrere Stunden alt ist. Gewöhnlich werden auch Informationen in regelmäßigen Abständen geloggt!
Aktuell ist der DC eingefroren und es geht nichts mehr. Ich werde heute Abend einen Snapshot vom Server anfertigen ehe ich ihn resete, dann kann ich die VM jederzeit wieder im aktuellen Zustand restoren um weitere Analysen durchzuführen!
Ist ein solches Verhalten generell schon einmal aufgetreten in der betreffenden UCS Version?
Vielen Dank im Vorraus!
Vg
Hendrik
Hello,
since my last update I have done to version 4.4-0, the server is freezing in irregular intervals. The Server responds to ping but https requests or SSH doesn’t work anymore!
A local console login seems to be working but after the username prompt it needs a few minutes to present the password prompt. After this I had waiting some hours before I hard turned the VM off. After a reboot the VM works without problems for 1 or 2 days. Than the same problem occure again!
I have checked the log files but it seems that the server stop logging when the problem occures.
At this moment the DC is frozen and the whole environment is down and not reachable!
Today at the evening I will create a VM snapshot. Than I can restore this VM in it’s current state for further analyses!
Is there a known problem it can occure such a problem?
Thank you in advanced!
/BR
Hendrik