Hallo Tschortschi,
aktuell bekomme ich folgendes Ergebnis vom laufenden DC:
free -h
total used free shared buff/cache available
Mem: 2,2G 1,2G 147M 27M 900M 865M
Swap: 7,9G 55M 7,8G
Der Server läuft seit etwas mehr als 5 Tagen.
top zeigt das folgende Ergebnis! Der Speicherverbrauch sortiert nach Prozess ist sehr sprunghaft:
top - 21:50:01 up 5 days, 2:36, 1 user, load average: 0,20, 0,10, 0,09
Tasks: 172 total, 4 running, 167 sleeping, 0 stopped, 1 zombie
%Cpu(s): 9,9 us, 4,2 sy, 0,0 ni, 85,3 id, 0,0 wa, 0,0 hi, 0,5 si, 0,0 st
KiB Mem : 61,9/2301264 [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| ]
KiB Swap: 0,7/8241148 [| ]
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1221 root 20 0 3376904 50700 17372 S 2,6 2,2 31:52.55 slapd
62969 root 20 0 40160 7268 4280 R 1,6 0,3 0:00.03 univention-moun
743 root 20 0 747488 88460 32784 S 1,1 3,8 6:17.96 named
62959 root 20 0 38008 3504 2936 R 1,1 0,2 0:00.42 top
1 root 20 0 205268 7468 5256 S 0,5 0,3 3:09.90 systemd
419 message+ 20 0 47308 3536 3072 S 0,5 0,2 1:43.84 dbus-daemon
428 root 20 0 38096 4556 3960 S 0,5 0,2 1:49.70 systemd-logind
1782 root 20 0 1368092 54960 4692 S 0,5 2,4 15:38.63 univention-mana
54632 root 20 0 689236 26268 14364 S 0,5 1,1 2:50.44 samba
62201 root 20 0 0 0 0 S 0,5 0,0 0:00.80 kworker/0:2
62966 root 20 0 107996 6468 5524 S 0,5 0,3 0:00.01 cron
62967 root 20 0 107996 6468 5524 S 0,5 0,3 0:00.01 cron
62968 root 20 0 107996 6468 5524 S 0,5 0,3 0:00.01 cron
62970 root 20 0 21140 5140 3120 R 0,5 0,2 0:00.01 univention-moun
62971 root 20 0 21532 5444 3160 R 0,5 0,2 0:00.01 univention-moun
63060 root 20 0 689228 29348 17580 S 0,5 1,3 10:09.61 samba
2 root 20 0 0 0 0 S 0,0 0,0 0:00.03 kthreadd
3 root 20 0 0 0 0 S 0,0 0,0 0:26.65 ksoftirqd/0
5 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 kworker/0:0H
7 root 20 0 0 0 0 S 0,0 0,0 1:22.72 rcu_sched
8 root 20 0 0 0 0 S 0,0 0,0 0:00.00 rcu_bh
9 root rt 0 0 0 0 S 0,0 0,0 0:00.00 migration/0
10 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0,0 0,0 0:01.21 watchdog/0
12 root 20 0 0 0 0 S 0,0 0,0 0:00.00 cpuhp/0
13 root 20 0 0 0 0 S 0,0 0,0 0:00.00 kdevtmpfs
14 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 netns
15 root 20 0 0 0 0 S 0,0 0,0 0:00.22 khungtaskd
16 root 20 0 0 0 0 S 0,0 0,0 0:00.00 oom_reaper
17 root 0 -20 0 0 0 S 0,0 0,0 0:00.00 writeback
18 root 20 0 0 0 0 S 0,0 0,0 0:00.00 kcompactd0
19 root 25 5 0 0 0 S 0,0 0,0 0:00.00 ksmd
Als gegenbeispiel der Status des hängenden DC, wiederhergestellt aus einem Snapshot:
free -h
![]()
top
[m]
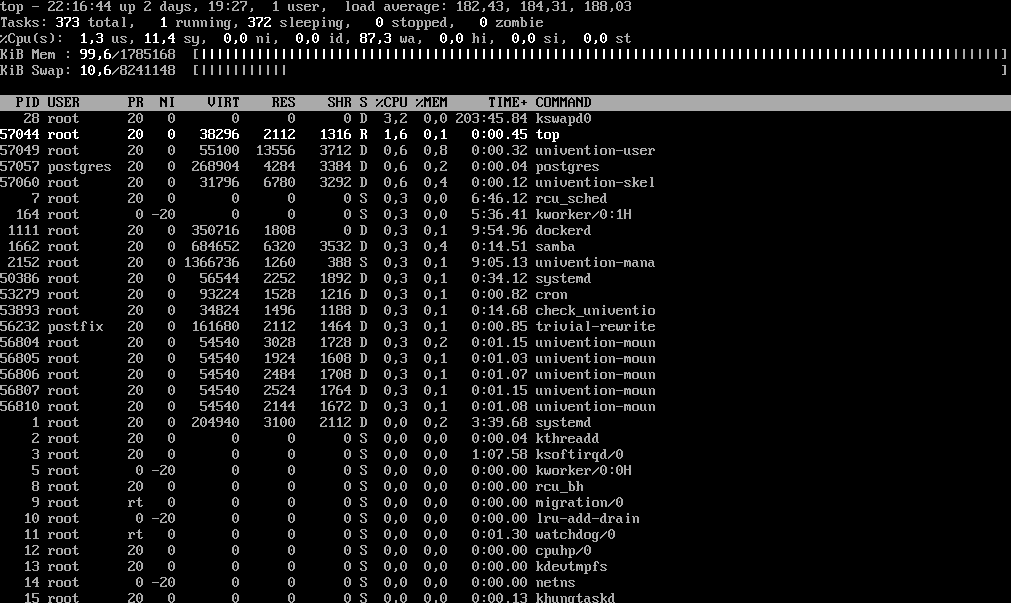
Ich habe noch eine weitere VM komplett frisch als DC installiert jedoch noch nicht aktiviert. Diese verhält sich ebenfalls ähnlich! Es wird Swap Speicher genutzt obwohl dies erst ab 60% Speicherbelegung statt finden sollte! Aktuell werden fast 60% genutzt.
Die Installation von htop klappt nicht. Ich habe es aber auch noch nicht weiter versucht!
Vg
Hendrik

