Since I run a 3-node Proxmox cluster with Ceph underneath, the Univention base is three domain controllers and then (currently) two VMs for playing around with NextCloud: if the App-store wasn’t mostly empty these days, there’d be more for other stuff, perhaps, but the control scope of Univention as a domain tool is much bigger and includes many physical machines running Windows and Linux.
For the domain controllers I just (thin) allocate a single 32GB disk, vastly more than it should ever need, but with thin allocation and discard/trim support that shouldn’t matter.
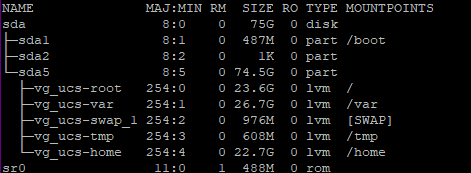
Within Debian/Univention I just create a single disk for everything, except that Debian evidently seems to do a separate swap even if I tell it to use the full disk… in any case I see that as a separate partition when looking inside the VMs, while /boot resides on an ext4 root partition, that’s used for everthing not swap.
Partitioning disks has its roots in ancient computer history, it’s mostly been used to avoid certain error scenarios or technical limitations (DOS PC disks had to be partitioned because FAT12 file systems were limited 32MB), while it reduces flexiblity and simplicity in most other ways.
And while you could alway boot DOS, Unix requires a bit more to just get running well enough to start fixing disk issues; the standard operationg procedure used to be a separate disk (or partition) for the OS, so disks/partitions/filesystems with the most user activity (and thus chances of errors/corruption) could be fixed while the relatively static boot/start OS disks/partitions would stay clean enough to enable at least a partial OS start.
In a VM environment those precautions may be much less necessary, because you can just mount your only drive to another OS instance to investigate issues and fix things. Whether that means you should avoid functional separation really depends too much on operational conditions and operator experiences to decide once and for all: read-only OS images that can always be rolled back to a snapshot, try to solve the problem, but edge cases persist.
Any advice I can give would be biased on my set of experiences and skills, often enough you need to trade simplicity of setup vs. simplicity of solving problems, resulting in the most complex setup in scenarios where availability targets hover around 0.9999% uptime.
And in my experience as someone who used to operate mission critical payment systems where 30 minutes of failure would have caused national headlines, while 5 minutes might just loose me the job, I don’t really trust smart automation as much as fault tolerance at all levels of design in combination with experience gained via testing failure handling before they happen.
Of course the home lab environment doesn’t need any of that, but the fact that VMs allow for easy snapshots and resumes allows you to gain experience much more easily on the “job”.
Perhaps the shortest variant would be: if your VM-system is one of many nearly equals, using one of those to fix an issue within something broken may be less effort in the long term than dealing with overflowing partitions. And while root and boot file systems can’t be extended while mounted, that limitation doesn’t exist on a system where you temporarily mount that disk as secondary. And if resizing in-place is not an option, anything in Unix/Linux can just be copied to a new and bigger virtual disk, which can then be used instead: no hidden files or odd fixed blocks any more, like in the old days when bootloaders couldn’t understand file systems.Transplanting an existing system to a new disk, something that used to be an entire industry in the Wintel-PC space, is so easy on Unix/Linux, nobody even talks about it… and that can become an issue for a younger generation. So I suggest you simply try that a few times, after snapshots/backups, of course, or perhaps on a discardable VM.
But typically the /boot partition simply shouldn’t be that small to become an issue, perhaps you gave the entire machine too small a disk, because you were thinking in full allocation terms and not thin allocation.
With today’s CPUs, SSDs and trim/discard the overhead of thin provisioning is most likely unnoticeable for most scenarios, so errors caused by tiny disks are more easily avoided.
Hope this helps!