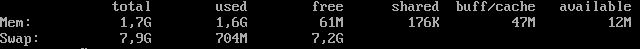wie gesagt war nur eine Idee… Ich selbst hab ESXi bei jedem meiner Kunden. Dort laufen UCS Installationen mit Kopano und Nextcloud.
Das Update habe ich auch bei jedem am vergangenen Wochenende Installiert. Bis jetzt kann ich nichts feststellen. Das macht mir ja schon bisschen Angst was du da schreibst
Hier in der Doku steht am Anfang
„Je nach geplantem Einsatzzweck und der Benutzeranzahl variieren die Systemanforderungen sehr stark. Mindestanforderungen für die Installation sind 1 GB Arbeitsspeicher und 8 GB Festplattenspeicher.“
thank you for your response and sorry for the delay! It seems we have exactly the same problem. At the moment it seems that my DC is working now but I have added lots of RAM capacity compared with the formerly scenario. Nevertheless i have the feeling that the system near to run into the problem again. Sometimes if I do any action on the server, I can see that the available capacity will be shrunk dramatically! For example I restart a service and I can see the available ram capacity will be reduced from 500MB to less than 50MB. Than I get back most capacity but not 500MB as before. Eventually I expect the DC shoud stop working after 5 days. Now it runs more than 7.5 days but i see the available RAM capacity is further shrunken.
The whole RAM capacity of the DC is 2.2GB before it was 1.25GB. The number of simultanusly used accounts are 2 Kopano accounts with authentication to the DC, thats it!
Meanwhile I noticed that the server runs into the problem too if it is completely isolated from each external connectivity. This means, turn the system on in it’s own area, wait and the system runs into this problem by it self! No user is connected, no other server, no internet, nothing but only loged in via text console! It looks there, that the server needs 2.2GB RAM at minimum only for running! Of course internal cron jobs are running!
vielen Dank! Ich habe, abgesehen vom Hypervisor nahezu das gleiche Setup! Bisher läuft mein DC noch. Ich habe allerdings das Gefühl, dass ich mir Betriebszeit über RAM erkaufen muss. Die benötigte Kapazität wird dann je nach Bedarf gigantisch und übersteigt die Mindestanforderungen deutlich.
Vielleicht kannst (oder solltest) Du bei Deinem Kunden einfach nur mal prüfen ob sich die RAM Verwaltung anders verhält als zuvor.
Vielen Dank besonders auch für die Links. Der zweite war mir noch nicht bekannt, zum ersten habe ich mir mehr Infos bezüglich der Anforerungen erhofft!
Hallo Hendrik, bis jetzt ist alles noch normal… es steht aber wieder ein update aus… vielleicht behebt das dein Problem…Bin gespannt was da rauskommt. Dann noch gutes Gelingen… bis da hin
haben die VMs denn genügend RAM? Mir scheint, wenn ich meine VMs mit reichlich RAM versorge kommt es nicht zu einem Problem bez. es beginnt entsprechend verzögert! Ich denke mal mit 4 - 8GB RAM sollte die VM dann einige Monate laufen. Bis dahin ist die Chance auf einen Neustart ohnehin relativ hoch!
Das Update hatte ich am Freitag eingespielt! Am Samstag morgen hatte ich fast 100 neue Mails da der DC nicht mehr erreichbar war! Den reboot habe ich nach über zwei Stunden abgebrochen in dem ich die VM hart ausgeschaltet habe!
Seitdem läuft sie erstmal wieder aber offenbar muss ich die VMs alle paar Tage nachts rebooten da sie so für den Dauerbetrieb nicht geeignet sind und das in einer Kleinstumgebung!
Ich habe zu Testzwecken einen aktuellen DC aufgesetzt mit nur 1.2GB RAM. Auch dieser läuft langsam voll! Da diese VM jedoch nichts tut als zu laufen, denke ich, das wird sich noch hinziehen ehe auch diese VM abstürzt! (Das ganze erinnert mich ein wenig an Windows 98)
Salve Hendrix,
melde dich mal mit ssh an der Maschine an und poste mal was da kommt
free -h
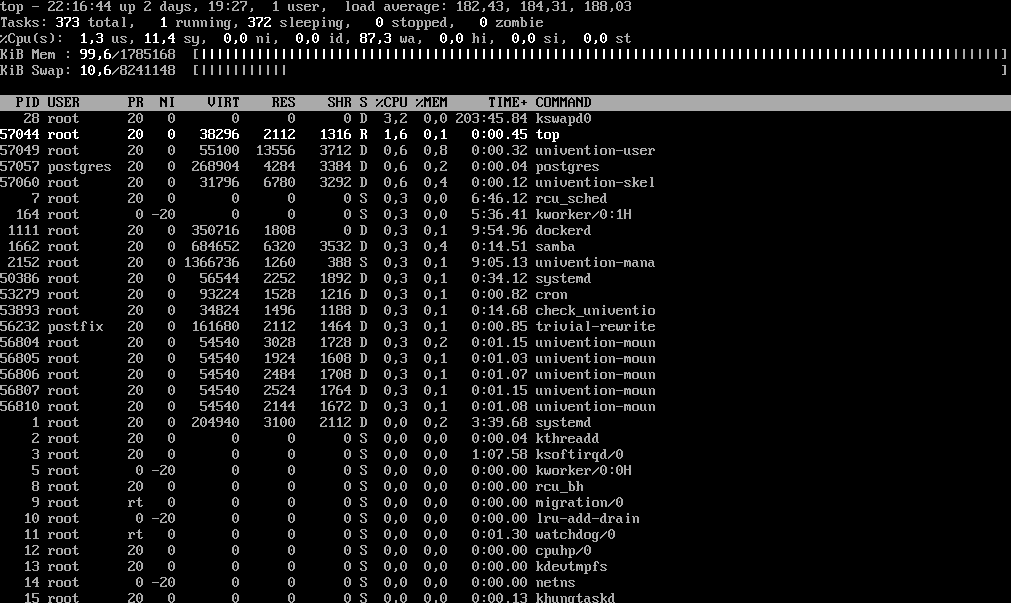
und dann mach mal den Befehl top danach m drücken… die Prozesse nach Speicherbedarf
mein Speicher einer meiner Maschine sieht so aus
root@mailmx:~# free -h
total used free shared buff/cache available
Mem: 7,8G 2,2G 2,9G 90M 2,6G 5,2G
Swap: 6,8G 0B 6,8G
mal sehen ob ich dir da helfen kann…
VG Tschortschi
Als gegenbeispiel der Status des hängenden DC, wiederhergestellt aus einem Snapshot:
free -h
top
[m]
Ich habe noch eine weitere VM komplett frisch als DC installiert jedoch noch nicht aktiviert. Diese verhält sich ebenfalls ähnlich! Es wird Swap Speicher genutzt obwohl dies erst ab 60% Speicherbelegung statt finden sollte! Aktuell werden fast 60% genutzt.
Die Installation von htop klappt nicht. Ich habe es aber auch noch nicht weiter versucht!
root@DC:~# grep '^memory' /proc/cgroups
memory 3 717 1
root@DC:~# grep pam_systemd /etc/pam.d/common-session
session optional pam_systemd.so
root@DC:~# ucr get pam/session/systemd
root@DC:~# univention-check-templates
WARNING: The following UCR files are modified locally.
Updated versions will be named FILENAME.dpkg-*.
The files should be checked for differences.
/etc/univention/templates/files/etc/nagios/nrpe.cfg
Hier das Ergebnis auf dem neu installierten Testserver:
das alte Setup lief über Monate mit 1,25GB für den DC und teilweise mit deutlich weniger für andere Server.
Ich habe die Kapazität in unterschiedlichen Test mehr als verdoppelt bis zu 4GB und dennoch kommt es zum einfrieren der VM, es dauert nur länger bis es passiert!
Die VM bekommt auch nicht ganz langsam immer mehr Probleme bis sie eben nur schlecht reagiert, der Speicherplatz steigt innerhalb kürzester Zeit sprunghaft an bis die Maschine nicht mehr nutzbar ist!
Es hilft nur ein Hardreset!
Sorry wenn ich das hier so schreibe aber hier läuft sogar Windows erhebleich zuverlässiger mit 4GB und einem installierten AD, DNS, DHCP und hat immer noch Platz für irgendwelchen Management Schnickschnack plus GUI und was sonst so niemand braucht wie AV…!
@MarcelBlock Dein Problem ist ein anders. Eröffne dafür bitte einen eigenen Thread; es bringt nichts, unterschiedliche Themen im selben Thread zu behandeln.
@hendrix3er Falls deine Installation bereits neu genug ist, kann es evtl. auch schon reichen, die common-session neu schreiben zu lassen und anschließend zu testen, ob pam_systemd wirklich auskommentiert ist:
das Problem scheint gelöst! Allerdings wird die Swap Disk immer noch recht schnell beschrieben!
Leider musste ich den Server nach 6 Tagen wegen einer Stromumschaltung abschalten. In sofern liefen die VMs nur 5 Tage bis zur Abschaltung!
Vielen Dank Moritz und allen Anderen für die Hilfe!