Hallo,
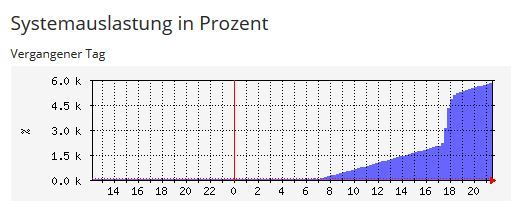
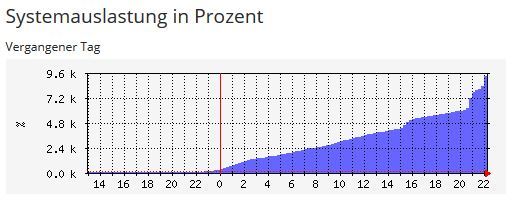
an den System-Stats fällt auf, dass die Last über den Tag schon relativ kontinuierlich steigt.
top - 06:00:02 up 1 day, 8:28, 0 share4, load average: 0.00, 0.03, 0.06
top - 06:00:05 up 1 day, 8:28, 0 share4, load average: 0.00, 0.03, 0.06
top - 06:30:02 up 1 day, 8:58, 0 share4, load average: 0.96, 0.33, 0.20
top - 06:30:05 up 1 day, 8:58, 0 share4, load average: 0.96, 0.33, 0.20
top - 07:00:02 up 1 day, 9:28, 0 share4, load average: 0.16, 0.21, 0.34
top - 07:00:05 up 1 day, 9:28, 0 share4, load average: 0.23, 0.22, 0.35
top - 07:30:01 up 1 day, 9:58, 0 share4, load average: 1.02, 1.07, 0.87
top - 07:30:04 up 1 day, 9:58, 0 share4, load average: 1.02, 1.07, 0.87
top - 08:00:02 up 1 day, 10:28, 0 share4, load average: 3.21, 2.37, 1.93
top - 08:00:05 up 1 day, 10:28, 0 share4, load average: 3.21, 2.37, 1.93
top - 08:30:02 up 1 day, 10:58, 0 share4, load average: 3.03, 3.06, 2.86
top - 08:30:05 up 1 day, 10:58, 0 share4, load average: 3.34, 3.13, 2.88
top - 09:00:02 up 1 day, 11:28, 0 share4, load average: 4.01, 4.06, 3.81
top - 09:00:05 up 1 day, 11:28, 0 share4, load average: 4.01, 4.06, 3.81
top - 09:30:02 up 1 day, 11:58, 0 share4, load average: 5.13, 5.10, 4.81
top - 09:30:05 up 1 day, 11:58, 0 share4, load average: 5.13, 5.10, 4.81
top - 10:00:02 up 1 day, 12:28, 0 share4, load average: 6.33, 6.20, 5.90
top - 10:00:05 up 1 day, 12:28, 0 share4, load average: 6.33, 6.20, 5.90
top - 10:30:01 up 1 day, 12:58, 0 share4, load average: 7.03, 7.14, 6.88
top - 10:30:04 up 1 day, 12:58, 0 share4, load average: 6.95, 7.13, 6.88
top - 11:00:02 up 1 day, 13:28, 0 share4, load average: 8.08, 8.04, 7.78
top - 11:00:05 up 1 day, 13:28, 0 share4, load average: 8.07, 8.04, 7.78
top - 11:30:02 up 1 day, 13:58, 0 share4, load average: 9.64, 9.24, 8.86
top - 11:30:05 up 1 day, 13:58, 0 share4, load average: 9.64, 9.24, 8.86
top - 12:00:02 up 1 day, 14:28, 0 share4, load average: 10.07, 10.11, 9.82
top - 12:00:05 up 1 day, 14:28, 0 share4, load average: 10.22, 10.14, 9.84
top - 12:30:02 up 1 day, 14:58, 0 share4, load average: 11.03, 11.09, 10.86
top - 12:30:05 up 1 day, 14:58, 0 share4, load average: 11.03, 11.09, 10.86
top - 13:00:02 up 1 day, 15:28, 0 share4, load average: 12.10, 12.20, 11.87
top - 13:00:05 up 1 day, 15:28, 0 share4, load average: 12.10, 12.20, 11.87
top - 13:30:02 up 1 day, 15:58, 0 share4, load average: 13.85, 13.24, 12.89
top - 13:30:05 up 1 day, 15:58, 0 share4, load average: 13.85, 13.24, 12.89
top - 14:00:02 up 1 day, 16:28, 0 share4, load average: 14.18, 14.10, 13.82
top - 14:00:05 up 1 day, 16:28, 0 share4, load average: 14.40, 14.15, 13.83
top - 14:30:02 up 1 day, 16:58, 0 share4, load average: 15.00, 15.03, 14.79
top - 14:30:05 up 1 day, 16:58, 0 share4, load average: 15.00, 15.03, 14.79
top - 15:00:02 up 1 day, 17:28, 0 share4, load average: 16.88, 16.36, 16.01
top - 15:00:05 up 1 day, 17:28, 0 share4, load average: 16.88, 16.36, 16.01
top - 15:30:01 up 1 day, 17:58, 0 share4, load average: 17.09, 17.07, 16.82
top - 15:30:05 up 1 day, 17:58, 0 share4, load average: 17.08, 17.07, 16.82
top - 16:00:02 up 1 day, 18:28, 0 share4, load average: 18.19, 18.10, 17.80
top - 16:00:05 up 1 day, 18:28, 0 share4, load average: 18.34, 18.13, 17.81
top - 16:30:02 up 1 day, 18:58, 0 share4, load average: 19.19, 19.12, 18.80
top - 16:30:05 up 1 day, 18:58, 0 share4, load average: 19.19, 19.12, 18.80
top - 17:00:02 up 1 day, 19:28, 0 share4, load average: 20.11, 20.12, 19.89
top - 17:00:05 up 1 day, 19:28, 0 share4, load average: 20.26, 20.16, 19.90
top - 17:30:02 up 1 day, 19:58, 0 share4, load average: 26.66, 24.05, 22.09
top - 17:30:05 up 1 day, 19:58, 0 share4, load average: 26.85, 24.13, 22.13
top - 18:00:02 up 1 day, 20:28, 0 share4, load average: 51.13, 49.97, 42.69
top - 18:00:05 up 1 day, 20:28, 0 share4, load average: 51.13, 49.97, 42.69
top - 18:30:02 up 1 day, 20:58, 0 share4, load average: 52.50, 52.24, 50.78
top - 18:30:05 up 1 day, 20:58, 0 share4, load average: 52.50, 52.24, 50.78
...
Die Samba-Prozesse sind bis 17:30 relativ unauffällig, sorgen aber dann für die Verdoppelung der Last. Hier sollte man ggf. auch mal schauen, was auf dem Client 192.168.100.23 zu diesem Zeitpunkt passiert.
Die stetig ansteigende Zahl der Prozesse ist allerdings nicht nur durch die Samba-Prozesse bedingt. Die halbstündlich laufenden cronjobs für die Session-Bereinigung von PHP aus /etc/cron.d/php5 werden nicht fertig und stapeln sich mit der Zeit. Das wäre aus meiner Sicht vielleicht als erstes zu prüfen.
Viele Grüße,
Dirk Ahrnke